
Hey,
It can be really frustrating when you can’t find an application that does exactly what you need. The best solution is often to build it yourself. That’s what motivated me, and here are a few reasons why:
- I want to create a low-cost application rather than paying for multiple subscriptions.
- I want full control over the features and design of the app.
- I want to build an ecosystem of apps that I can explore and expand myself, especially with AI integration.
Hiragana / Katakana
So what I need just remember word, because almost of the time I’m write in the textbook, so one application to help recheck knowledge like ABCD is good enough
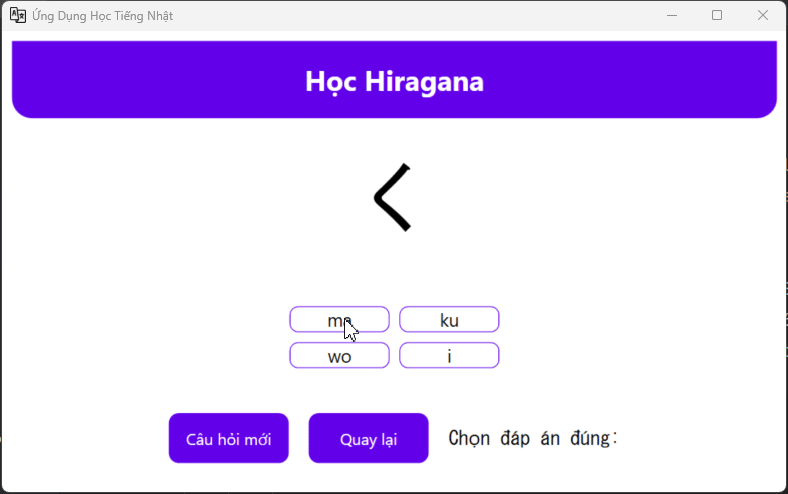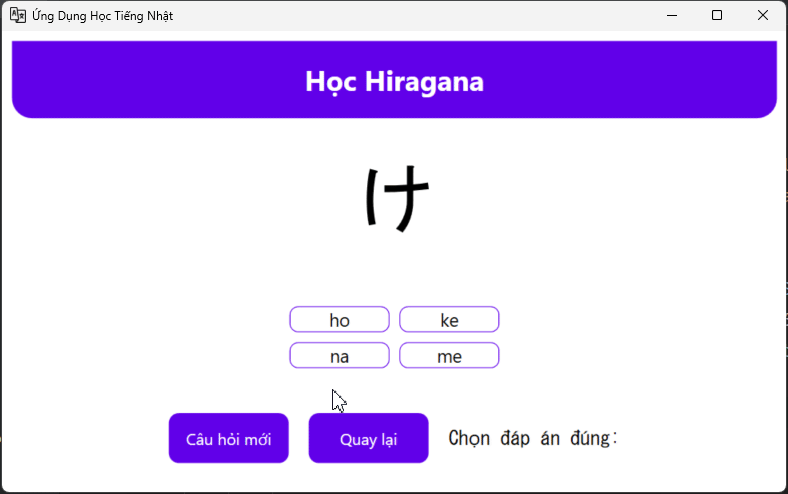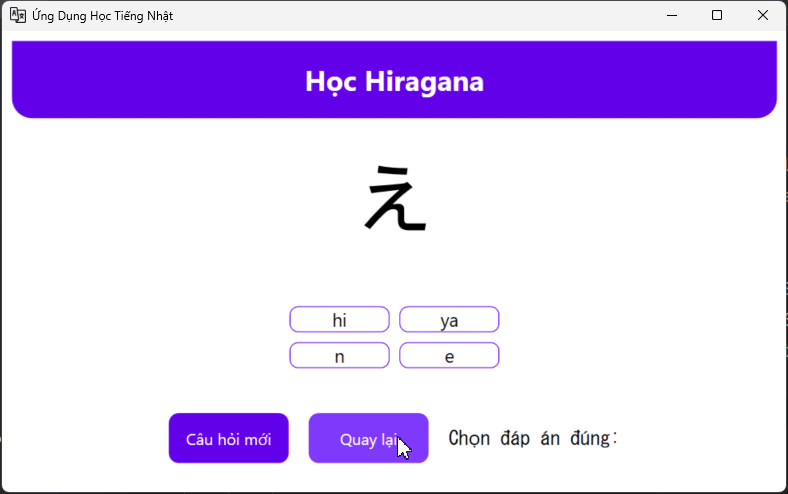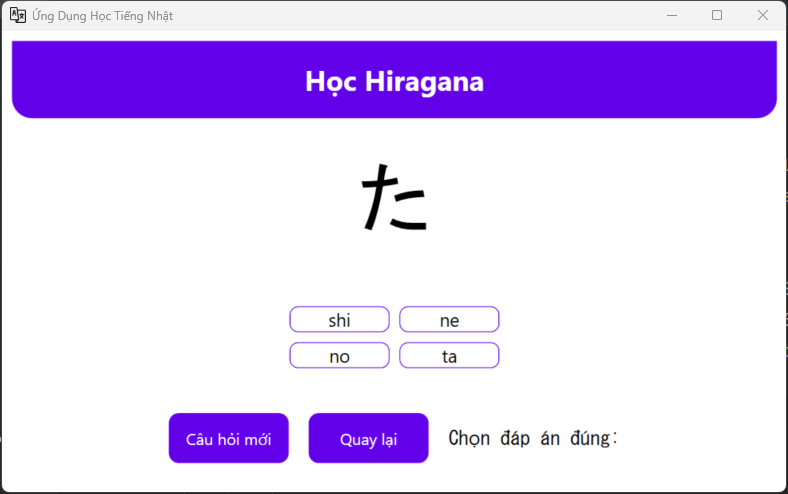
Hiragana / Katakana Q&A
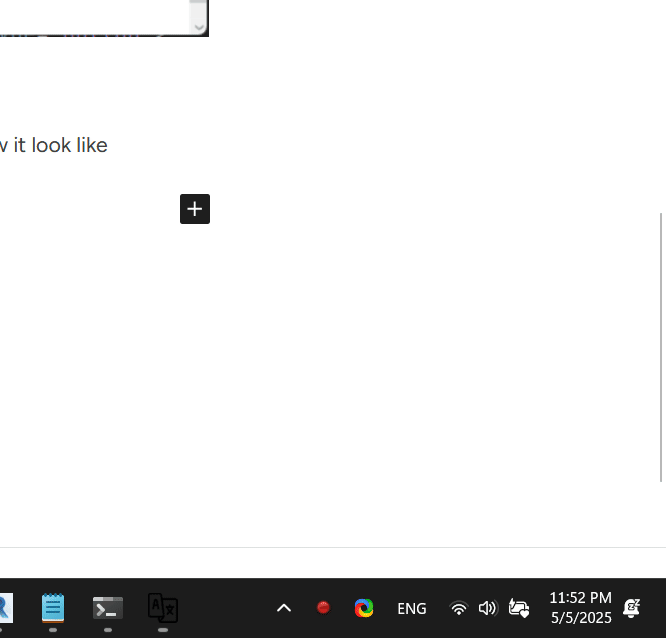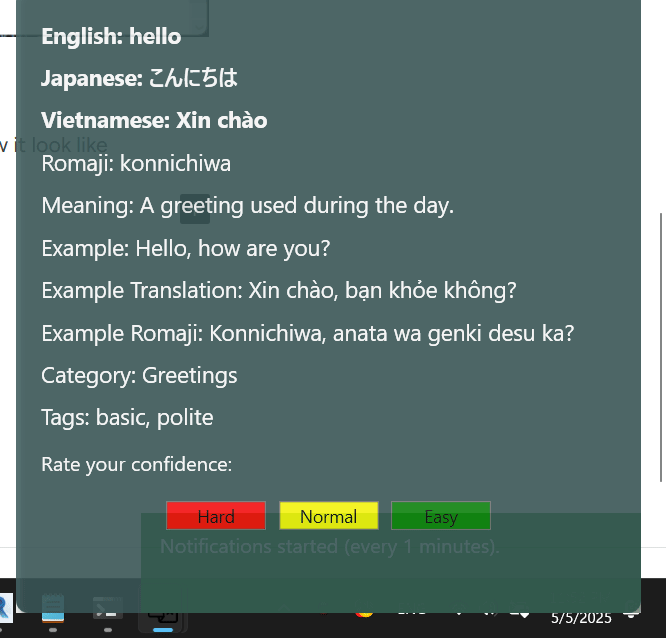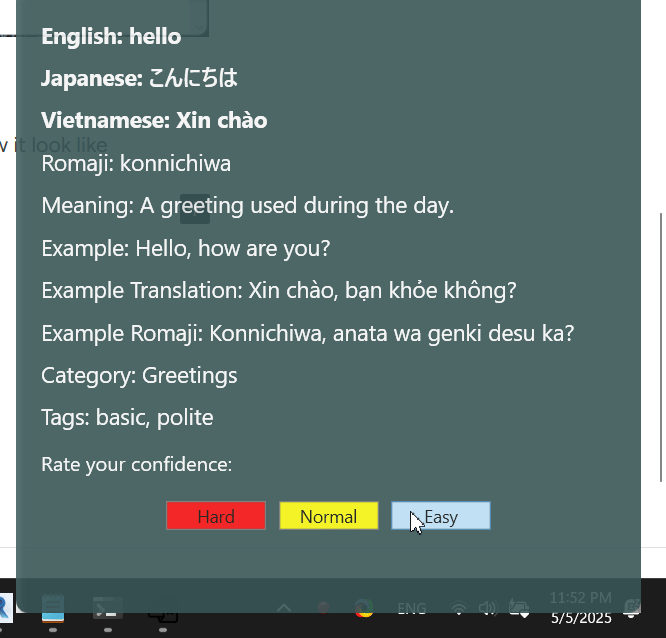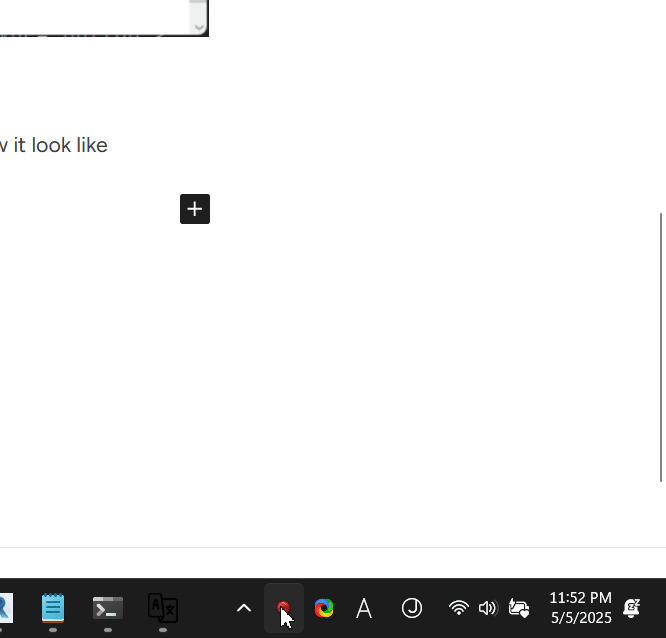
I want check faster after writing, it will look like this, every time I click wrong , I need to relearning it again inside the textbook
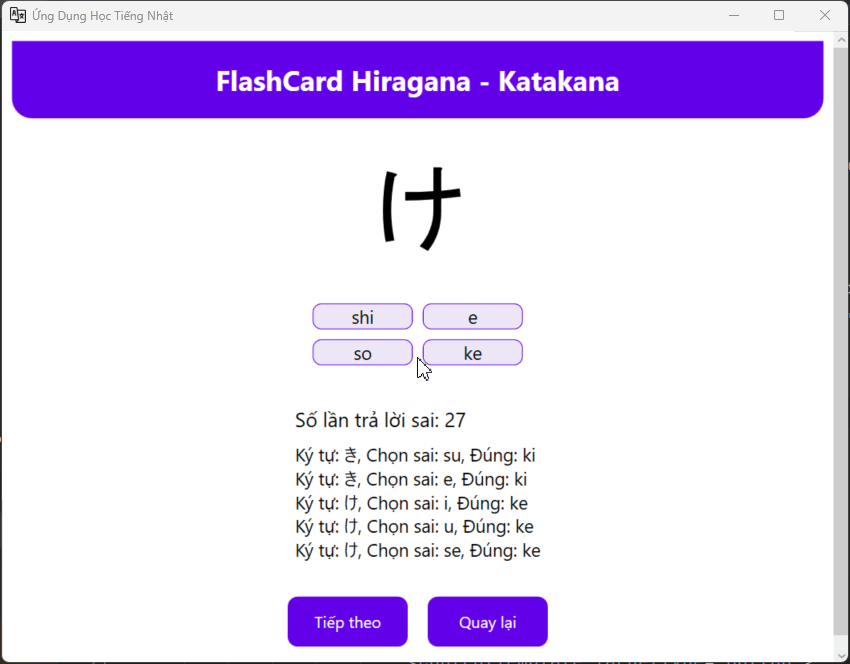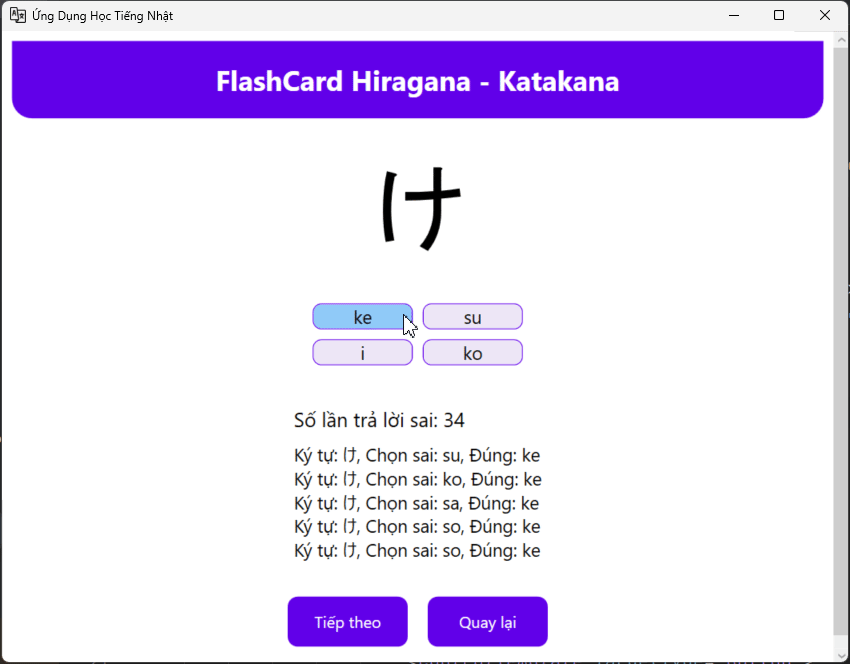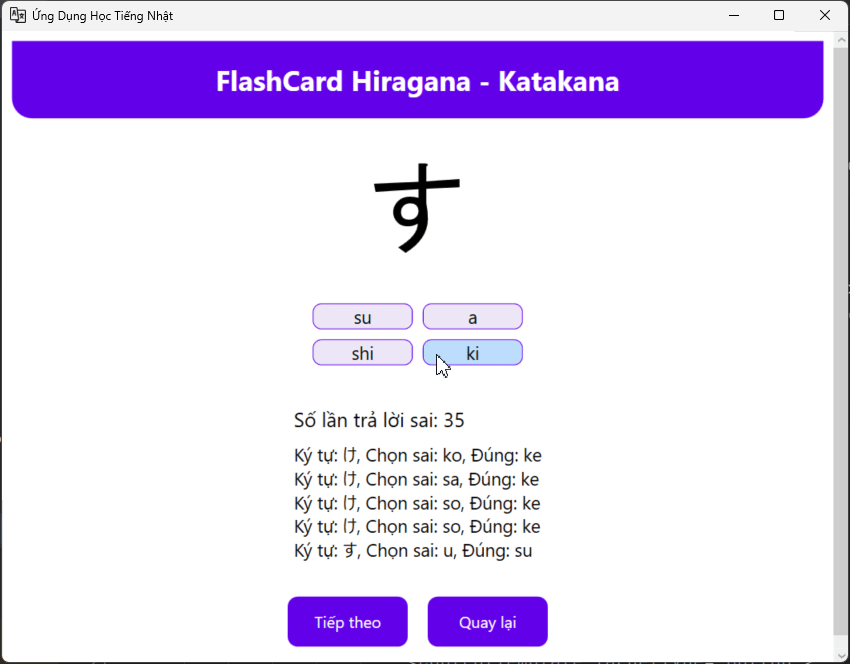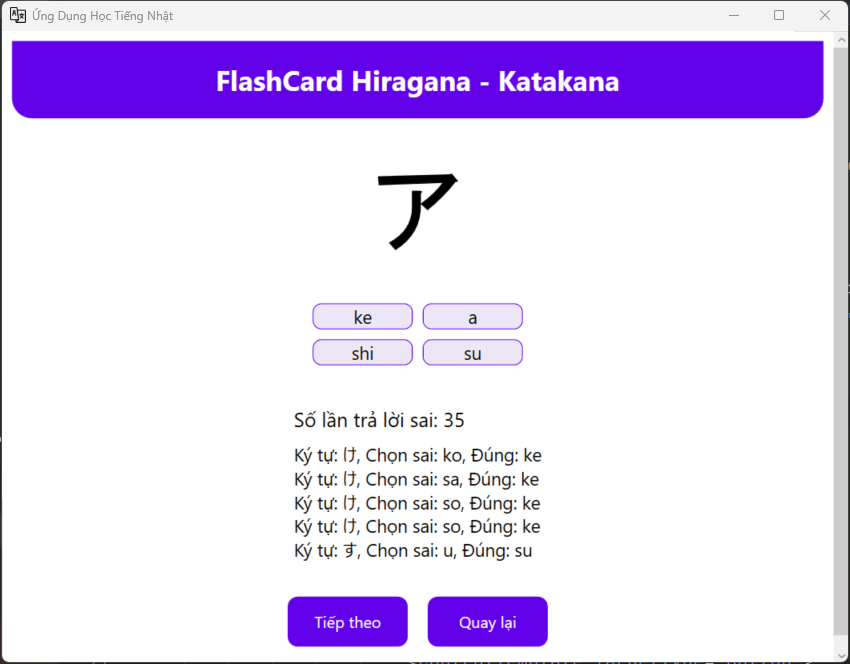
Flash Card
I will copy the future same like Anki App remember the level of word I remembered for next time show.
I want to make an notification for learning every time minutes I will set. So this is how it look like.
This is the database I designed to connect with n8n and integrate with the AI system.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
CREATE TABLE words ( word_id SERIAL PRIMARY KEY, japanese VARCHAR(255) NOT NULL, english VARCHAR(255), vietnamese VARCHAR(255), romaji VARCHAR(255), meaning TEXT, example TEXT, example_translation TEXT, example_romaji TEXT, category VARCHAR(255), tags VARCHAR(255), created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE study_sets ( set_id SERIAL PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE study_set_words ( set_id INT REFERENCES study_sets (set_id) ON DELETE CASCADE, word_id INT REFERENCES words (word_id) ON DELETE CASCADE, PRIMARY KEY (set_id, word_id) ); CREATE TABLE IF NOT EXISTS history ( history_id SERIAL PRIMARY KEY, word_id INT NOT NULL REFERENCES words (word_id) ON DELETE CASCADE, set_id INT REFERENCES study_sets (set_id) ON DELETE SET NULL, difficulty VARCHAR(50) DEFAULT 'Normal', next_show_index INT DEFAULT 0, show_count INT DEFAULT 0, last_reviewed TIMESTAMP, CONSTRAINT unique_word_set UNIQUE (word_id, set_id) ); |
The AI system will generate the schema and continuously add new words or sets to the dictionary, allowing the SQL database to learn and expand over time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[ { "English": "hello", "Japanese": "こんにちは", "Vietnamese": "Xin chào", "Romaji": "konnichiwa", "Meaning": "A greeting used during the day.", "Example": "Hello, how are you?", "ExampleTranslation": "Xin chào, bạn khỏe không?", "ExampleRomaji": "Konnichiwa, anata wa genki desu ka?", "Category": "Greetings", "Tags": "basic, polite" }, |
Finally, VPS from server will need to do :
- Create a PostgreSQL database to store the data and connect it to the application.

- Create rest API to connect into n8n
And finally, we can connect it to n8n to integrate AI workflows.
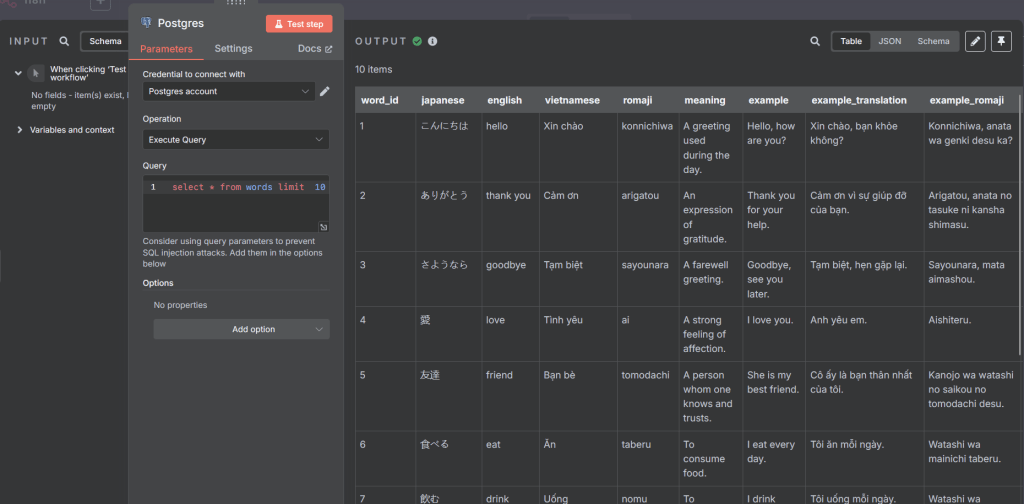
It seems to be working well now 😊. I know there’s still a lot to improve, but for now, it’s good enough for me. The application only took three days to develop, so I can’t expect too much yet.
I hope this helps you get the idea too!